Beyond NCCL: Faster Inter-Node All-Reduce for Decode-Heavy LLM Inference
Introduction
As large language models grow in size, a single node — typically 4-8 NVLink-connected GPUs — is no longer sufficent to hold the model and run inference. Models like Llama-405B or Nemotron-Ultra-253B can require 16–32 GPUs even for modest batch sizes. On most HPC systems, that means stepping outside the comfort of NVLink into the slower world of inter-node networking, where communication costs dominate.
So what’s the best way to run inference in this multi-node world?
For moderate context lengths (a few thousand tokens), there are two main distributed inference strategies:
Tensor Parallelism (TP) splits each layer’s weights across GPUs and requires an All-Reduce collective after each matrix multiply.
Pipeline Parallelism (PP) splits the model into contiguous subsets of layers. It requires only point-to-point communication but introduces sequential dependencies and pipeline “bubbles.”
Conventional wisdom says that TP within a node and PP across nodes is the best strategy, as it reduces the inter-node message volume. But on HPC systems, with advanced interconnect fabrics like Slingshot or InfiniBand, the trade-off isn’t that simple:
- PP reduces inter-node message volume, but also introduces sequential dependencies and pipeline bubbles. This shows up in single-batch offline inference scenarios where pipeline latency scales with number of nodes.
- TP has a high message volume, but also parallelizes all the matrix multiplications.
LLM Inference Beyond a Single Node
To understand how LLM frameworks scale beyond a single node in offline single-batch inference scenarios, we built YALIS (Yet Another LLM Inference System), a light-weight and performant inference engine prototype that gives us full instrumentation flexibility. We validate its performance against vLLM and run strong scaling experiments for both frameworks on the Perlmutter supercomputer (4X NVIDIA 80GB A100s per node connected via NVLink; Slingshot-11 interconnect between nodes). Our experiment here uses the Llama-3.1-70B-Instruct model with a batch size of 16, prefill length of 2480, and decode length of 2048.
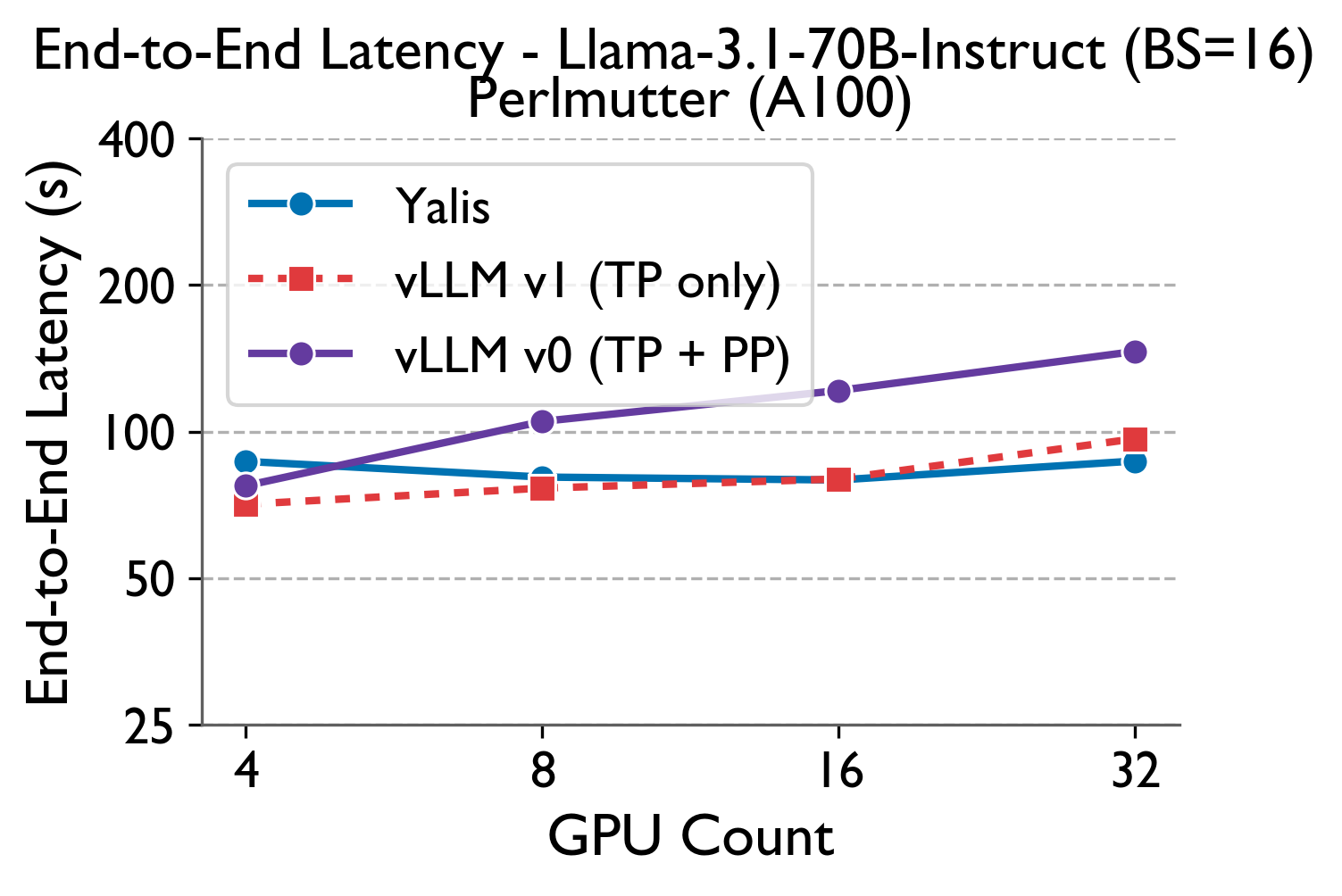
Findings: Using the common wisdom TP+PP approach, end-to-end latency increases with increasing GPU/node count. Remember that under ideal strong scaling (fixed total problem size with increasing GPU count), latency should decrease with increasing resources. None of the parallelism strategies achieve that, with TP+PP being the worst. We believe this is due to the fact that PP is suited more to online high throughput scenarios where a constant influx of batches can hide pipeline bubbles and hide the sequential dependencies.
A Deeper Look with YALIS
Noting that YALIS performs similar to vLLM, we instrument YALIS to get detailed breakdowns and understand what is going on. We study separately the two phases of LLM inference: prefill and decode. We subcategorize the time spent in each of these phases into: Matmul (Time spent in matrix multiplications), Communication, FlashAttn (Time spent in FlashAttention), Other (Time spent in all other GPU operations), Idle (GPU Idle Time).
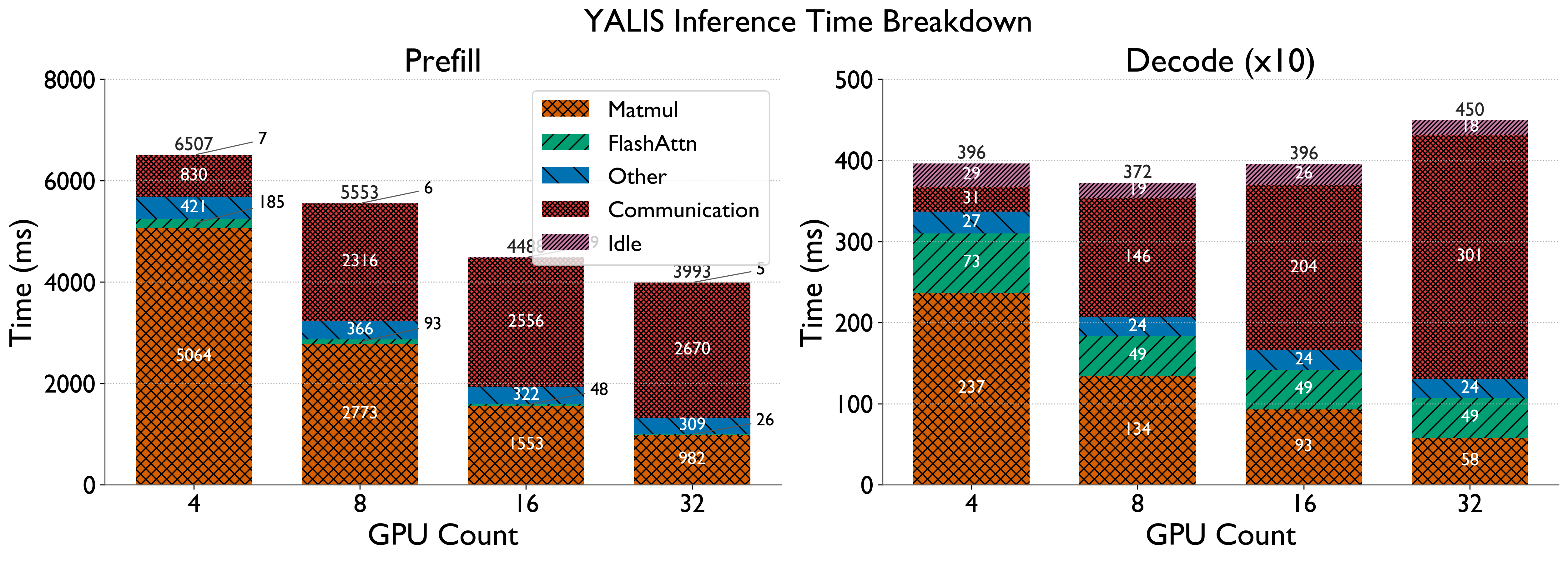
Findings: The compute time (Matmul + FlashAttn + Other) decreases as expected, demonstrating ideal strong scaling with increasing GPU count. However, the communication time blows up substantially going from single to multi-node. At 32 GPUs, it is >50% of the time for both prefill and decode.
This shows that communication is a big bottleneck for both prefill and decode. While both phases do All-Reduce communication among the GPUs, there is a key difference in the two phases with respect to the All-Reduce message sizes. In this particular example, the prefill All-Reduce message size is 620 MiB (very large message regime), whereas the decode All-Reduce message size is 256 KiB (small message regime).
Beyond NCCL — Tailoring All-Reduce for Decode
Next, we turned our focus to communication in the decode phase. Although prefill also suffers from communication overhead, decode is the bigger concern for generation-heavy workloads: its auto-regressive token-by-token nature — issuing many small, latency-sensitive messages — dominates end-to-end latency.
Most inference frameworks rely on NCCL (on NVIDIA systems) for collective communication. While NCCL excels within a node for small messages, its performance drops once communication crosses nodes. On non-NVLink interconnects (without NVSwitch), NCCL typically uses either Ring All-Reduce or Tree + Broadcast All-Reduce. But are these algorithms optimal for the small-message, low-latency regime of decode? Other collective libraries, such as MPI, offer a broader range of algorithms — including recursive approaches that are theoretically better here — but lack features important for inference, like CUDA graph friendliness and low kernel launch overhead.
Seeing this gap, we set out to design something better. Our answer - NVRAR: a GPU-initiated NVSHMEM Recursive All-Reduce implementation , tuned for decode’s small message sizes beyond a single node, and built to integrate cleanly with CUDA graphs and low-overhead inference. NVRAR uses a heirarchical approach, leveraging NCCL for intra-node Reduce-Scatter and All-Gather and a custom inter-node Recursive All-Reduce implementation with low synchronization overhead.
Early experiments with NVRAR show consistent speedups over NCCL in the decode message size regime.
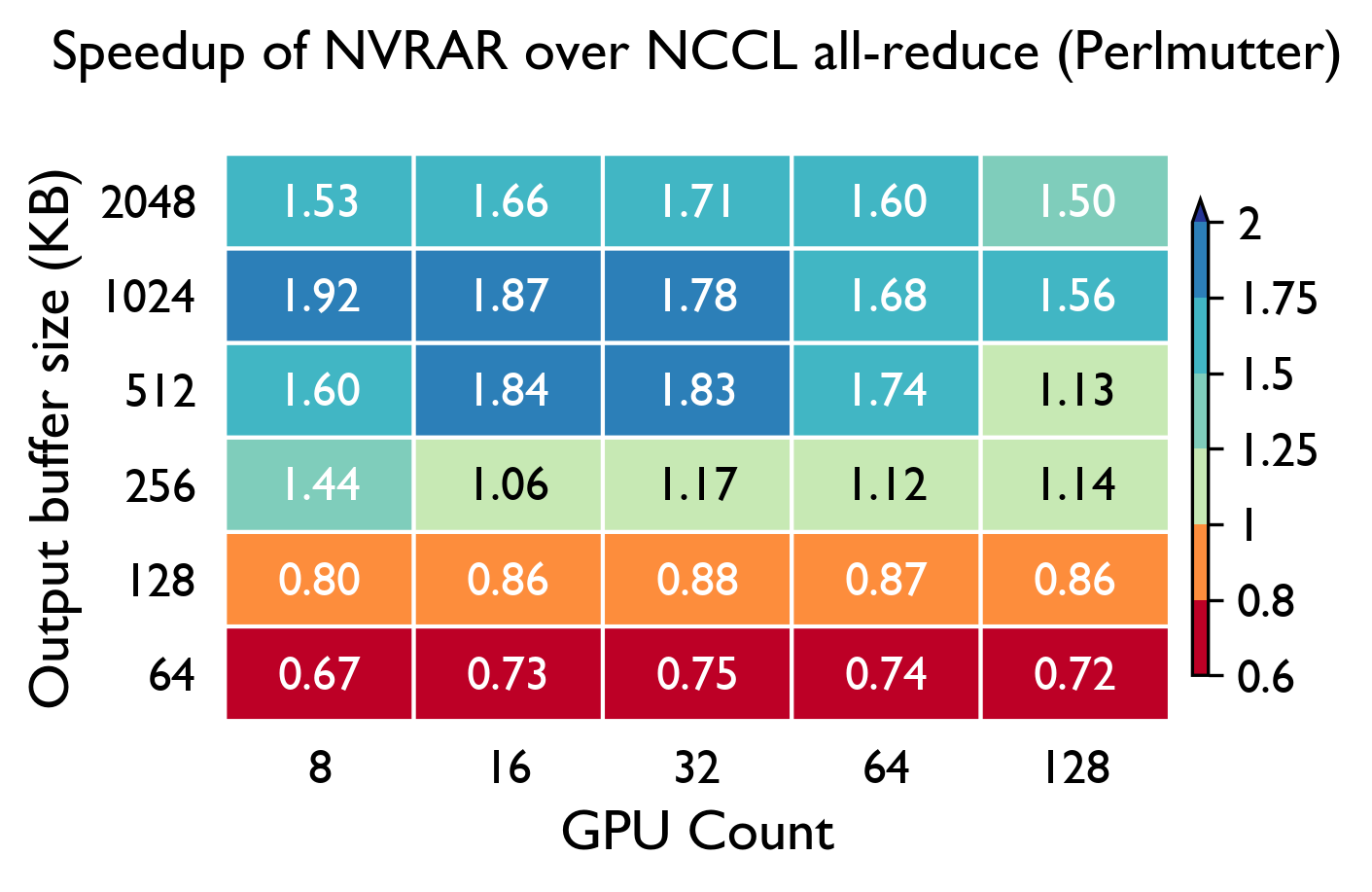
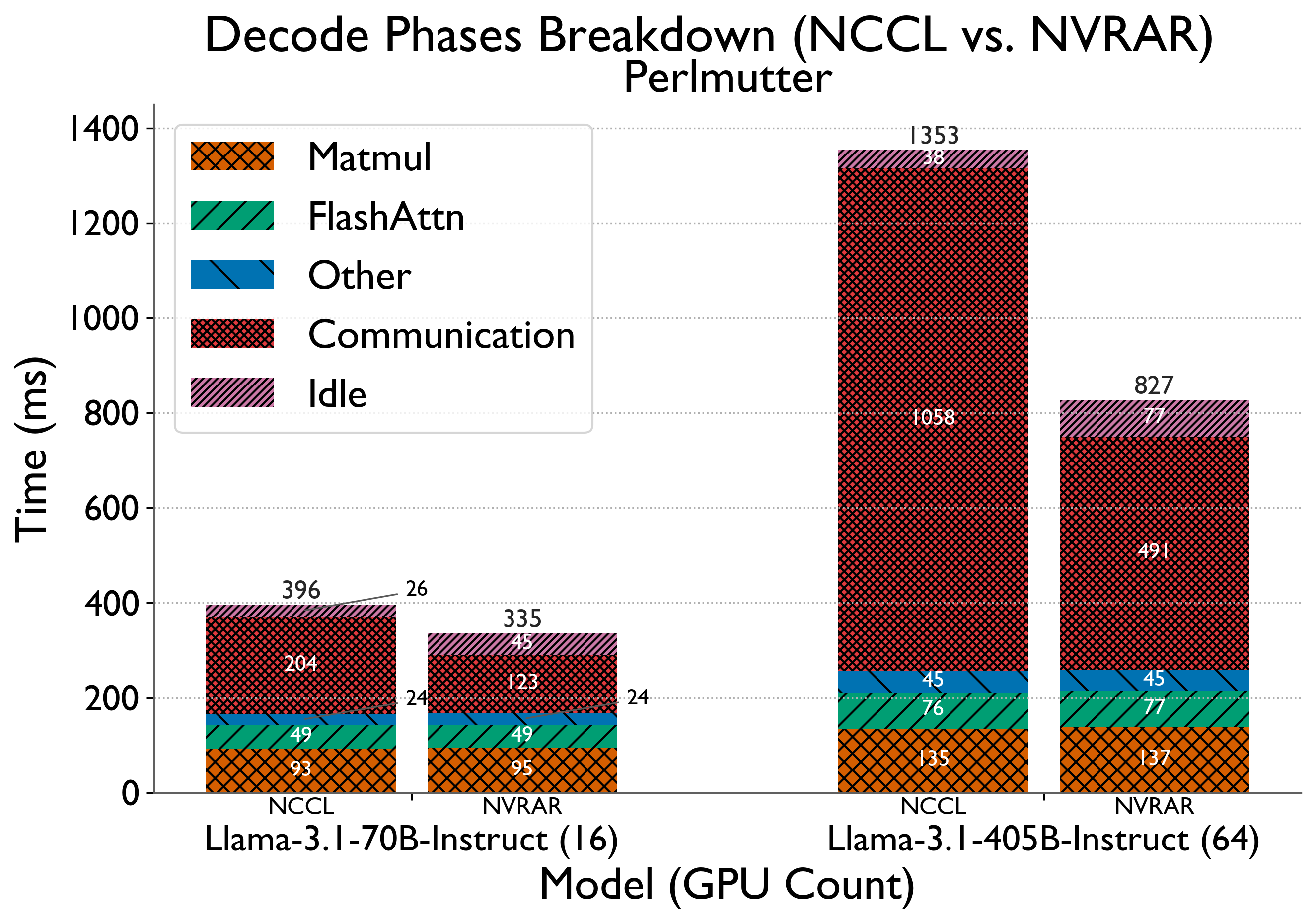
Findings: NVRAR achieves modest speedups compared to NCCL in the 256 KiB to 2 MiB message size range. Further, when plugged into YALIS, we see a reduction in decode latencies (TBT times) by up to 15% for Llama-3.1-70B Instruct on 16 GPUs, and 38.8% for Llama-3.1-405B-Instruct on 64 GPUs.
We’re also making both YALIS and NVRAR open-source so that others can experiment, benchmark, and provide feedback. The full design details and extended evaluation can found in our paper.