Optimizing Inference for AI Models
The transformer architecture has revolutionized the field of deep learning. Large Language Models have grown exponentially larger in size since the introduction of the architecture. The largest models of today require gigantic amounts of compute and memory, both during training and when inferencing the trained model. Further, the attention mechanism, which is at the core of the transformer architecture, becomes a significant bottleneck for long sequence inference due to the auto-regressive nature of the models. Unlike training, which is a one-time process, inference happens continuously once the model is deployed. Hence, it becomes critical to design systems and techniques that can reduce the compute and memory cost of inference, translating to a significant dollar cost reduction in running these models. This research project aims to explore and develop algorithms for efficient inference of AI models.
Recent Publications
Epidemic Modeling
Controlling the spread of infectious diseases in large populations is an important societal challenge, and one which has been highlighted by current events. Mathematically, the problem is best captured as a certain class of reaction-diffusion processes (referred to as contagion processes) over appropriate synthesized interaction networks. Agent-based models have been successfully used in the recent past to study such contagion processes. Our work revolves around the development of Loimos, a highly scalable parallel code written in Charm++ which uses agent-based modeling to simulate disease spread over large, realistic, co-evolving networks of interaction.
HPC Data Analytics
Hundreds to thousands of jobs run simultaneously on HPC systems via batch scheduling. MPI communication and I/O data from all running jobs use shared system resources, which can lead to inter-job interference. 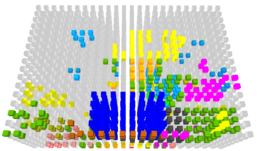
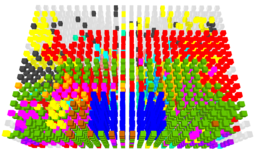 This interference can slow down the execution of individual jobs to varying degrees. This slowdown is referred to as performance variability. The figures to the right shows two identical runs of an application (in blue) with the rest of the system differing, yet they experienced a nearly 25% difference in messaging rate. Application-specific data and system-wide monitoring data can be analyzed to identify performance bottlenecks, anomalies and correlations between disparate sources of data. Such analytics of HPC performance data can help mitigate performance variability, and improve application performance and system throughput.
This interference can slow down the execution of individual jobs to varying degrees. This slowdown is referred to as performance variability. The figures to the right shows two identical runs of an application (in blue) with the rest of the system differing, yet they experienced a nearly 25% difference in messaging rate. Application-specific data and system-wide monitoring data can be analyzed to identify performance bottlenecks, anomalies and correlations between disparate sources of data. Such analytics of HPC performance data can help mitigate performance variability, and improve application performance and system throughput.
Our research uses data analytics of system-wide monitoring data and “control” jobs data to identify performance bottlenecks, anomalies, and correlations. We use this data to predict variability in future jobs and make resource-aware job schedulers.
Recent Publications
Parallel Code Foundry: LLMs for HPC
Large Language Models (LLMs) are increasingly demonstrating their ability to improve the software development process. In this area of research we focus on how to improve LLMs for HPC, parallel, and scientific software development. Our work includes evaluation of the state-of-the-practice when applying LLMs to parallel coding tasks, improving LLMs at these tasks, and creating LLM-powered developer tools for HPC.
Recent Publications
Parallel Deep Learning
The emphasis on training increasingly large neural networks has gained prominence in deep learning research over recent years (see Figure). This trend arises from the consistent observation by practitioners that the generalization capability of neural networks improves reliably with an increase in their sizes. However, this significant increase in the number of parameters is accompanied by an unintended consequence: a substantial increase in the hardware resources required for training these neural networks. The era of training large models on a single GPU or even a single node comprising a few GPUs is now a thing of the past. The extensive computational and memory requirements of training these multi-billion-parameter models necessitates harnessing hundreds to thousands of GPUs in parallel.
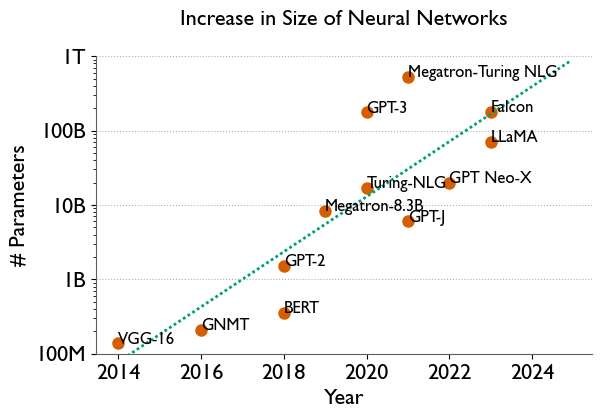
The goal of this research project is to develop an efficient and highly scalable parallel framework for training large neural networks, addressing the core challenges that arise with model scaling. Our approach focuses on two primary objectives:
-
Minimizing Inter-GPU Communication Overhead: As models grow in size, the amount of data that needs to be exchanged between GPUs increases significantly, which can lead to substantial slowdowns due to communication bottlenecks. To address this, we are exploring techniques for optimizing communication, such as overlapping computation with communication and autotuning the parameters of distributed deep learning algorithms via performance modelling. By reducing the communication overhead, we aim to ensure that the GPUs spend most of their time on computation rather than waiting for data, leading to faster and more efficient training of large-scale models.
-
Ensuring User-Friendly Implementation: While performance optimization is crucial, ease of use is equally important for broad adoption. Training large models in a distributed environment is often seen as a complex and error-prone task, requiring significant expertise in distributed systems and GPU management. Our goal is to simplify this process by providing a high-level interface that abstracts away the complexity of parallelization. Practitioners should be able to easily transform their existing single-GPU or single-node training code into a distributed training setup without needing deep knowledge of hardware details or parallel computing.
Together, these efforts are packaged in AxoNN, an open-source framework that aims to deliver both the performance required to handle cutting-edge, large-scale models and the simplicity needed for widespread usability. AxoNN empowers researchers and developers to train massive neural networks on distributed infrastructures without the traditional complexities associated with parallel computing, ultimately accelerating innovation in AI research and applications.
Recent Publications
Performance Portability
This project aims to improve the performance of scientific applications on diverse hardware platforms through performance portability. Heterogeneous, accelerator-based hardware architectures have become the dominant paradigm in the design of parallel clusters, and maintaining separate versions of a complex scientific application for each architecture is highly undesirable for productivity. As a result, portable programming models such as Kokkos, RAJA, and SYCL have emerged, which allow one code to run on multiple hardware platforms, whether powered by NVIDIA, AMD, or Intel GPUs and CPUs. However, how well these models enable not just single-source correctness but single-source performance across all target systems is not well-understood. We are conducting a comprehensive study of applications and mini-apps from a wide range of scientific domains implemented with multiple programming models across hardware architectures and vendors to analyze how well the available programming models enable performance portability.
Recent Publications
Performance Tools
We are working to develop data analysis and visualization tools for analyzing the performance of large-scale parallel applications, as well as higher-level tools for automating performance analysis tasks. Our programmatic data analysis tools include Hatchet for profile analysis and Pipit for trace analysis. We are also conducting comparative work to evaluate the accuracy of call graphs generated by profiling tools. Finally, we are working to enable automatic diagnosis of performance bugs in GPU kernels based on performance data.
Recent Publications
Past Research
Hypersonics
Computational fluid dynamics (CFD) solvers are essential for understanding and predicting turbulent hypersonic flows, providing a critical resource for the timely development of atmospheric and space flight technologies as well as improving climate science. However, the sensitivity of hypersonic turbulence demands a high degree of numerical fidelity in simulations.
Existing approaches have been shown to achieve good performance on CPU-based systems using only MPI, but the emergence of GPU-based supercomputing platforms has created a new opportunity to further improve performance. In addition, adaptive mesh refinement (AMR) can massively decrease the amount of work required to achieve a given level of fidelity. In this project, we have adapted an existing hypersonics CFD code that was MPI-only to include support GPU acceleration and AMR using the AMReX library, adapting our use of AMReX to handle previously-unsupported curvilinear grids in interpolation and data management. This cumulatively results in substantial orders-of-magnitude reductions in time-to-solution on representative benchmarks.
Recent Publications
Parallel File Systems
The research project is to build an efficient file system for high-performance computing (HPC) applications. Developing user-level filesystems for specific workloads requires analyzing the I/O behavior of parallel programs, and identifying I/O bottlenecks and limitations. Based on the analysis, strategies can be developed to improve I/O performance. The project involves studying the I/O behavior of several HPC benchmarks and applications. It also involves analyzing the collected data to identify bottlenecks, and then developing strategies to mitigate those bottlenecks.