HPC Data Analytics
In recent years High Performance Computing (HPC) systems have begun to collect and store significant amounts of monitoring data through tools like LDMS. Additionally, there has been the development of tools for programmatic analysis and collection of performance related data for applications. These data allow us to both study previous trends on HPC systems as well as develop techniques based on these insights to better utilize resources.
Performance Variation
One important problem we can address with this data is performance variation on HPC clusters. Due to the use of shared resources for communication and I/O, applications can experience significant variation in their run times. The figure below shows an example of the variation in run time for several HPC proxy applications. This is problematic for many reasons. It delays scientific progress as researchers cannot accurately gauge the performance of their code. It reduces net system utilization as many jobs will run slower. Finally, many parts of the HPC software ecosystem rely on users being able to accurately provide run time estimates, such as to a job scheduler.
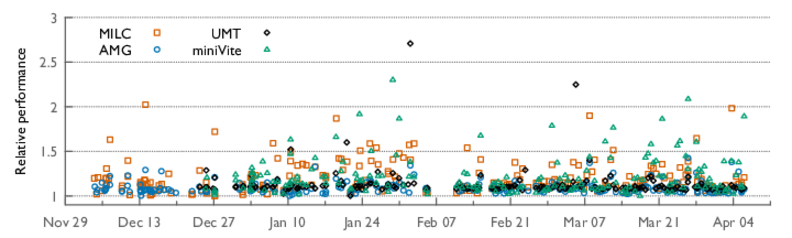
Numerous papers have studied the causes and effects of performance variation [1]. Some recent works have even looked at mitigating variation, however, many of these look at a singular component of variation (such as message routing). A more holistic approach to preventing variation would be to tackle it from the system scheduler, which is in charge of resource management. This is the approach we have taken in our work on RUSH.
RUSH: Resource Utilization-aware Scheduler for HPC
RUSH [2] is a scheduling framework designed to mitigate variation in jobs without limiting job run time or the throughput of the scheduler. It consists of 2 main components: variation prediction and variation-aware scheduling. These are highlighted in the image below.
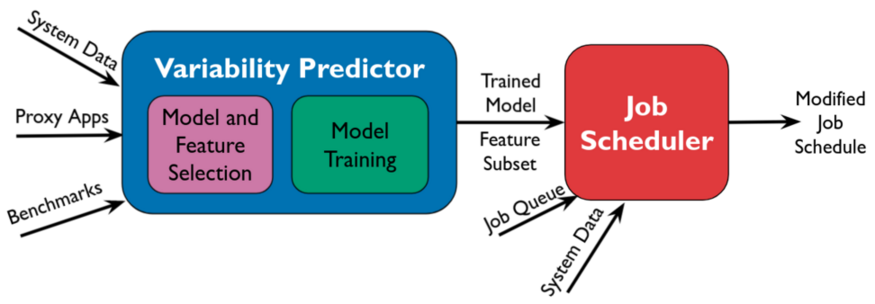
The first component of the pipeline is the variation prediction module. Here we use machine learning to predict if variation is going to occur. The model’s input is an encoding of the application’s computation type (network, i/o, or computation bound) and the system state from the last 5 minutes provided by LDMS counters. The model’s output is then the classification of whether variation will occur for this job or not. We train this model by running many applications for several months and recording the performance and system counters. In [2] we are able to achieve an F1 score of 0.95 on this training task.
Finally, we use this prediction in a system batch scheduler. The RUSH scheduling algorithm delays the scheduling of jobs for which the ML model predicts variation by putting them back in the queue. It also imposes a hard limit on the number of times a job can be skipped to prevent starvation. In [2] we show that an implementation of RUSH reduces the number of jobs experiencing variation from 17 to 4 (76% decrease) in our test job set. We also find that RUSH can reduce the max run time of an application by up to 5.8%.
For more details on this work please see “Resource Utilization Aware Job Scheduling to Mitigate Performance Variability”.
Related Publications
[1] Abhinav Bhatele et al, "The case of performance variability on dragonfly-based systems", Proceedings of the IEEE International Parallel & Distributed Processing Symposium. IEEE Computer Society, May 2020
[2] et al, "",