Parallel Code Foundry: LLMs for HPC
Large Language Models (LLMs) are increasingly demonstrating their ability to improve the software development process. Because of this there has been a recent explosion in tools and research that target integrating LLMs into code development processes and even creating new types of tools. Incorporating these approaches into HPC, parallel, and scientific code development has the potential to drastically improve the quality and quantity of software in these fields moving forward. However, HPC code has different concerns and priorities than other areas of computer science, such as a larger emphasis on performance, parallelism, and fidelity. Likewise special attention is needed when designing LLM-based tools for HPC, so that these priorities remain integral in the design.
This broad effort includes several subprojects, which can be found in several of our recent publications [1-6] and the Parallel Code Foundry GitHub organization. Specific projects include:
- Creating benchmarks for LLMs’ abilities at generating fast parallel code
- Developing HPC-centric developer tools powered by LLMs
- Empowering LLMs to translate HPC software at the whole-repository level
- Fine-tuning and aligning LLMs to improve their capabilities at HPC-related tasks
ParEval: Evaluating LLM Capabilities for Parallel Code Generation
A crucial step towards creating HPC-specific LLMs is being able to evaluate an LLM’s capabilities on HPC tasks. It is further helpful to identify the shortcomings of current state-of-the-art models to find areas where improvement is needed. In order to conduct this evaluation we created the ParEval benchmark. ParEval is a set of 420 code generation problems ranging across 7 execution models and 12 different computational problem types. Alongside ParEval we also introduced novel metrics for understanding the runtime performance and scaling behavior of LLM generated code.
The plot on the right shows the ParEval pass@1 scores for both serial and
parallel code generation for several state-of-the-art open and closed-source
LLMs.
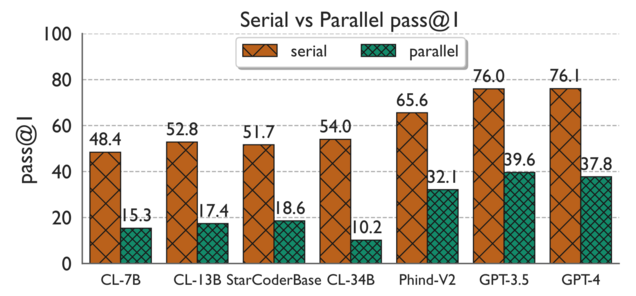 A higher pass@1 score indicates the model more frequently generates correct code
across the benchmark. We immediately see that, while some models are better than
others, all of the LLMs are much worse at generating parallel code than they are
serial. Unfortunately, we also observe that commercial LLMs generate parallel
code much better than open-source LLMs. This motivates the need for open-source
LLMs that can generate parallel code well and can compete with commercial
models.
A higher pass@1 score indicates the model more frequently generates correct code
across the benchmark. We immediately see that, while some models are better than
others, all of the LLMs are much worse at generating parallel code than they are
serial. Unfortunately, we also observe that commercial LLMs generate parallel
code much better than open-source LLMs. This motivates the need for open-source
LLMs that can generate parallel code well and can compete with commercial
models.
An up-to-date list of model scores is available on the ParEval Leaderboard. You can find more details on ParEval and an extensive analysis of the results in our HPDC ‘24 paper “Can Large Language Models Write Parallel Code?” [4]. The prompts and source code for ParEval are available at github.com/parallelcodefoundry/ParEval.
ParEval-Repo: Employing LLMs for HPC Whole Program Translation
As part of the ParEval effort, we found that LLMs are generally better at translating to parallel execution models from existing code than they are at using parallel execution models from scratch, but are still not accurate enough to be reliable for translation tasks in a parallel context. However, the ParEval benchmark tests only LLM capabilities at translating single functions. Most realistic translation tasks will involve working with entire codebases that need to be rewritten in a new execution model. Developing appropriate techniques to improve LLM capabilities at whole program translation requires appropriate benchmarks, similar to ParEval, which evaluate performance at translating full code repositories. To address this need, we introduced ParEval-Repo, which utilizes popular scientific proxy applications as well as custom mini-apps as translation test cases for small to medium scale repository translation. These tasks require the LLM to not only translate the parallel code itself but also the parallel library initialization and build systems.
As shown below, for all LLMs tested, generating translations that can compile correctly is very difficult, let alone generating a correct or performant translation. These results include testing with both a simple single static prompt (Non-agentic) as well as a simple agentic framework that proceeds file by file and passes forward relevant context from prior translations (Top-down agentic). We present both the code-only score (where the build system files were written by a human) and the overall score, which scores the LLM generation of all code and build system files.
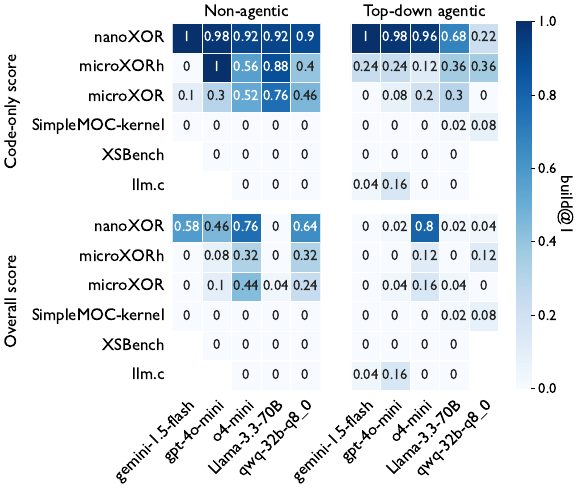
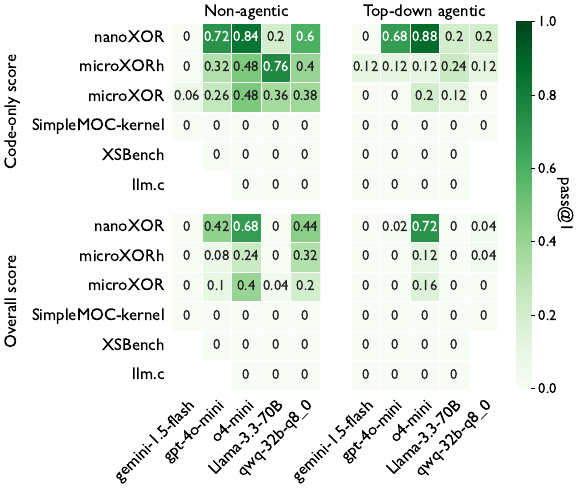
Using our ParEval-Repo benchmark suite, we are studying methods to improve the performance of the most promising state-of-the-art open-source LLMs at these translation tasks. Our goal is to enable a workflow in which the user can provide an entire scientific application codebase to our tool and get in return the same codebase converted to a different programming language or GPU programming model. We are building an agentic LLM framework that can directly interact with and gain feedback from the parallel hardware and compiler, as well as freely explore the repository directory and file layout, function calls, class inheritance, and other structural features to gain context for translation.
Improving LLMs for HPC Tasks
Based on the results across the ParEval benchmark we know that current state-of-the-art LLMs are bad at generating correct and efficient parallel code. To address these shortcomings we have introduced two fine-tuning methodologies for creating HPC-specific code LLMs [1,3] and aligning the output space of current code LLMs with performance so that they generate faster code [2].
The first of these efforts introduced HPC-Coder, an LLM fine-tuned on HPC data and evaluated on several HPC development tasks. We demonstrated how fine-tuning existing code LLMs on large datasets of HPC code can improve their ability to write HPC and parallel code. This fine-tuned model was further evaluated on the tasks of labeling for-loops with OpenMP pragmas and predicting performance regressions across git commits. You can read more about how HPC-Coder was trained and evaluated in our ISC ‘24 paper “HPC-Coder: Modeling Parallel Programs using Large Language Models” [3].
Developers most often parallelize code to obtain better performance meaning
parallel code that is correct, but inefficient is not of much use.
 Since ParEval
showed us that LLMs can often generate inefficient parallel code we developed a
technique called RLPF for fine-tuning LLMs to generate faster code. RLPF is
inspired by the popularity of reinforcement learning human feedback (RLHF) where
reinforcement learning (RL) is used to align LLMs with human preferred
outputs. We adapt this approach to use RL to align code LLMs with faster
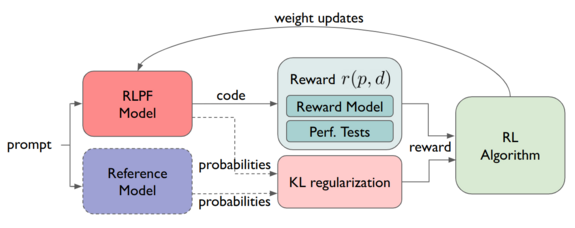
outputs. An overview of our RLPF approach is displayed on the left.
Since ParEval
showed us that LLMs can often generate inefficient parallel code we developed a
technique called RLPF for fine-tuning LLMs to generate faster code. RLPF is
inspired by the popularity of reinforcement learning human feedback (RLHF) where
reinforcement learning (RL) is used to align LLMs with human preferred
outputs. We adapt this approach to use RL to align code LLMs with faster
outputs. An overview of our RLPF approach is displayed on the left.
We were able to accomplish this by combining a large coding contest dataset
with synthetically generated data to obtain a large, general performance dataset.
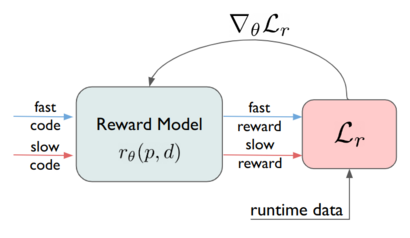 Using this data we trained a code performance reward model and used it,
in conjunction with performance tests, as a reward function in our RL training.
An overview of the reward model training is depicted on the right.
RLPF fine-tuning was able to improve the expected performance of generated
code from the Deepseek Coder LLMs across a variety of tasks.
Using this data we trained a code performance reward model and used it,
in conjunction with performance tests, as a reward function in our RL training.
An overview of the reward model training is depicted on the right.
RLPF fine-tuning was able to improve the expected performance of generated
code from the Deepseek Coder LLMs across a variety of tasks.
You can read more about RLPF and find a detailed analysis of our results in our arxiv paper “Performance-Aligned LLMs for Generating Fast Code” [2]. In this paper we further explored other performance alignment fine-tuning methods and also evaluated the LLMs on their performance optimization capabilities.
Related Publications
[1] Daniel Nichols et al, "Modeling Parallel Programs using Large Language Models", Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’23, November 2023
[2] et al, "",
[3] Daniel Nichols et al, "HPC-Coder: Modeling Parallel Programs using Large Language Models", Proceedings of the ISC High Performance Conference
[4] Daniel Nichols et al, "Can Large Language Models Write Parallel Code?", Proceedings of the 33rd International Symposium on High-Performance Parallel and Distributed Computing
[5] Aman Chaturvedi et al, "HPC-Coder-v2: Studying Code LLMs Across Low-Resource Parallel Languages", Proceedings of the ISC High Performance Conference
[6] Joshua H. Davis et al, "ParEval-Repo: A Benchmark Suite for Evaluating LLMs with Repository-level HPC Translation Tasks", Proceedings of the 54th International Conference on Parallel Processing, September 2025.