Parallel Deep Learning
Parallel deep learning workloads are characterized by large communication to computation ratios. This is because computation is relatively inexpensive on modern GPUs and has outpaced the increase in network bandwidth on GPU-based clusters with size. Hence, the design and implementation of efficient communication algorithms is critical to prevent starvation of GPUs waiting for data to compute on. To this end, we have been developing a framework for parallel deep learning, AxoNN [1], which addresses this issue in a two-pronged fashion.
-
Asynchronous message-driven execution of neural network operations Contemporary frameworks for parallel deep learning are inefficient because they use synchronous point-to-point NCCL communication primitives for exchanging activations and gradients. AxoNN uses a MPI-based point-to-point communication backend that exploits asynchrony to overlap communication and computation and thus increase hardware utilization. It also implements a novel message-driven scheduler that enables the execution of neural network operations in the order in which their data dependencies are met.
-
Memory optimizations for improving performance AxoNN also implements memory optimizations that can save up to 5x memory required to store the model states. These memory optimizations allow us decrease the number of GPUs required to house a single instance of a neural network and thus decrease the ratio of computation to point-to-point communication. We observe that these memory optimizations can improve training performance by up to 13% on neural networks with as many as 12 billion parameters[1].
Below, we compare AxoNN with NVIDIA’s Megatron-LM and Microsoft’s DeepSpeed on several multi-billion parameters models. These two frameworks have been used to train some of the largest neural networks in existence. Together, our optimizations make AxoNN the state-of-the-art for training large multi-billion parameter neural networks.
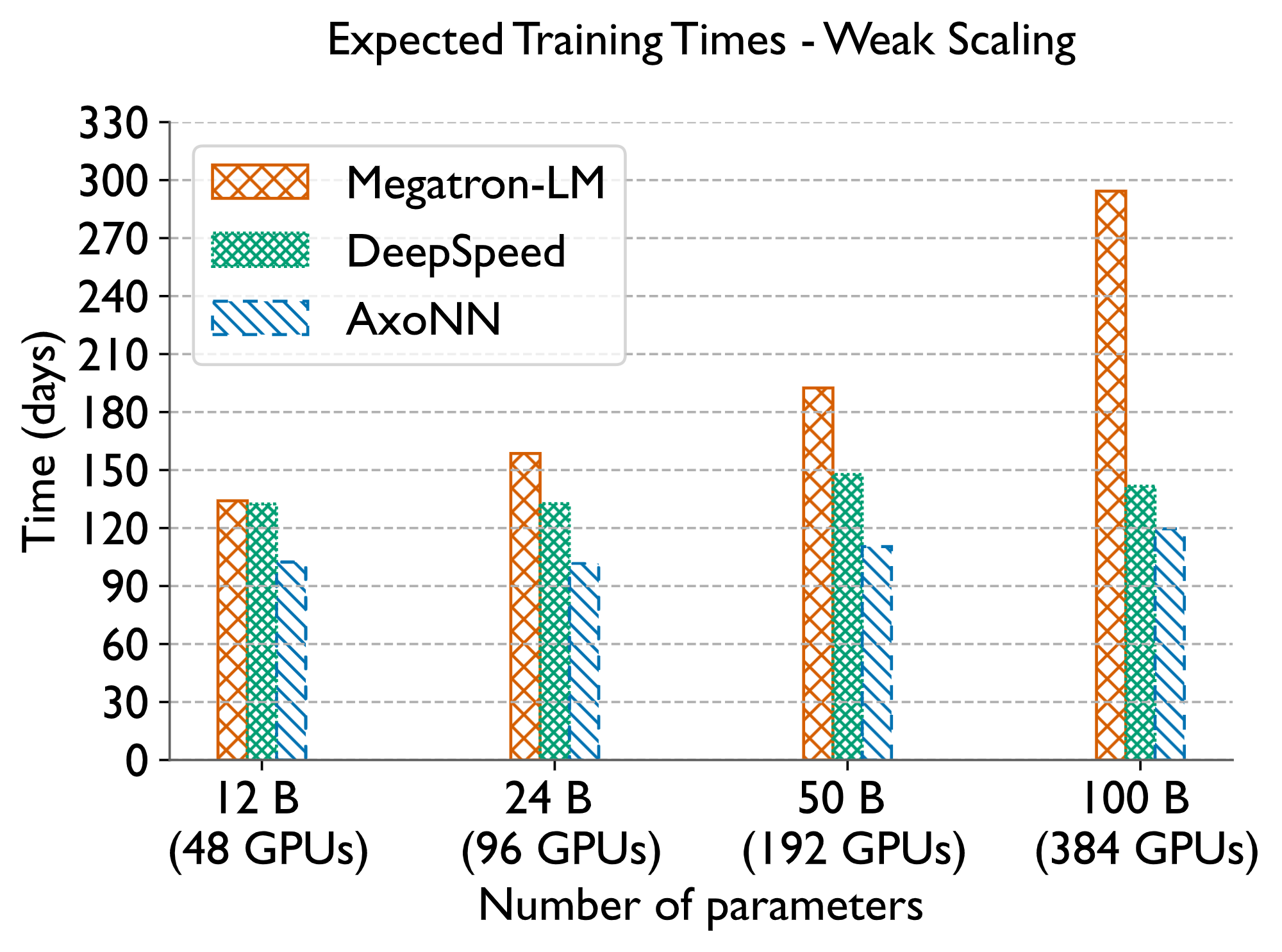
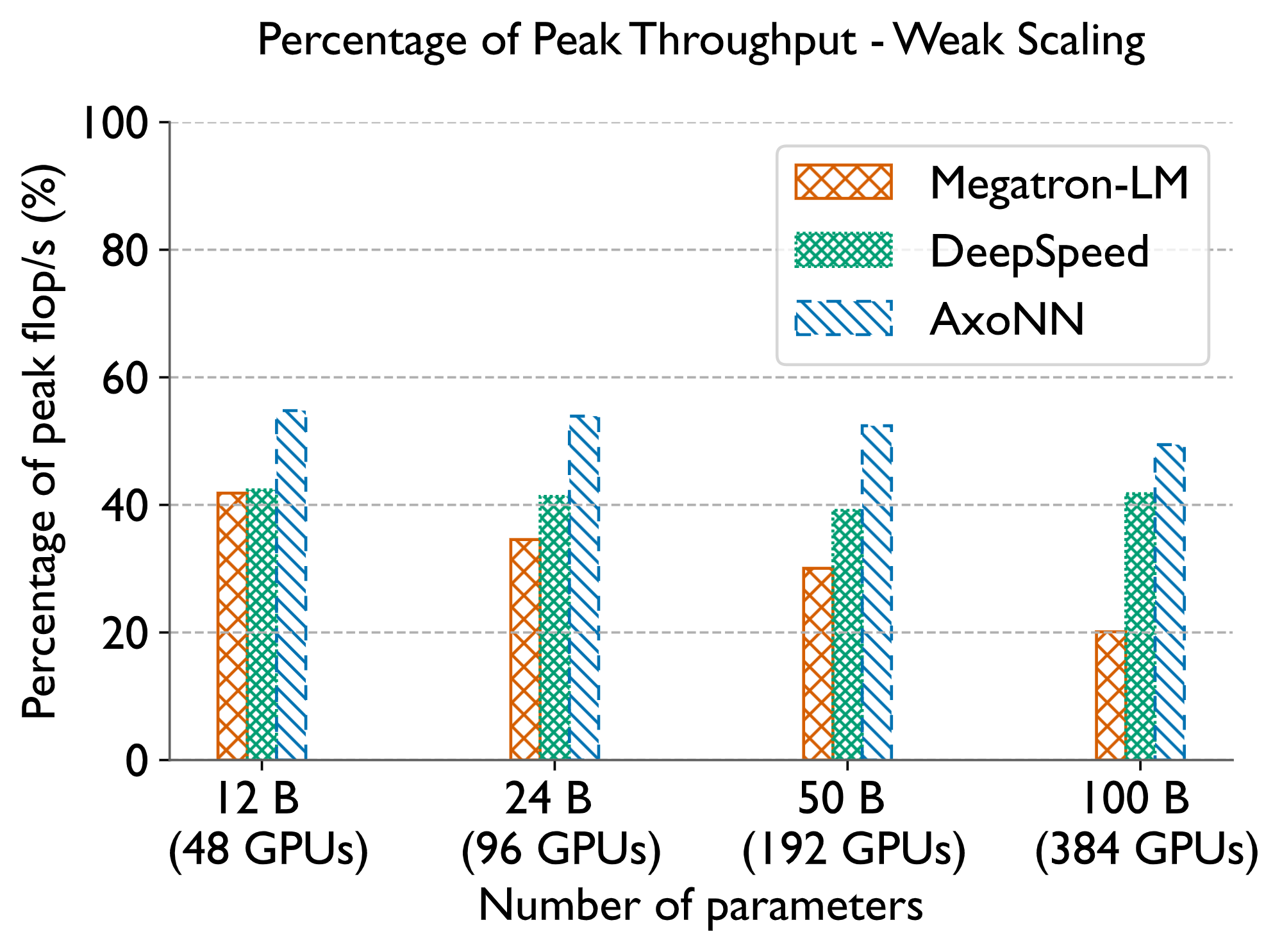
Related Publications
[1] Siddharth Singh et al, "AxoNN: An asynchronous, message-driven parallel framework for extreme-scale deep learning", Proceedings of the IEEE International Parallel & Distributed Processing Symposium. IEEE Computer Society, May 2022
[2] Siddharth Singh et al, "Exploiting Sparsity in Pruned Neural Networks to Optimize Large Model Training", Proceedings of the IEEE International Parallel & Distributed Processing Symposium. IEEE Computer Society, May 2023
[3] et al, "",
[4] Siddharth Singh et al, "Democratizing AI: Open-source Scalable LLM Training on GPU-based Supercomputers", Proceedings of the ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis, November 2024