Performance Portability
With the increasing dominance of heterogeneous platforms with diverse GPU vendors, using HPC machines efficiently for scientific applications demands performance portability, the capability of codes to achieve high performance across a range of target platforms. Developers might address this by creating multiple specialized code versions of an application to optimize performance for each target system. However, this divergence in code creates a significant burden for maintenance and development. Thus, there is a strong need for programming models that enable single-source performance portability in scientific applications. However, choosing a programming model for porting a CPU-only application to GPUs is a major commitment, requiring significant time for developer training and programming. If a programming model turns out to be a ill-suited for an application, resulting in an unacceptable performance, then that investment is wasted.
Thus, we are working to address the developer’s dilemma of choosing a programming model by providing a comprehensive empirical study of programming models in terms of their ability to enable performance portability on GPU-based platforms. We use a variety of proxy applications implemented in the most popular programming models and test them across multiple leadership-class production supercomputers.
Programming Models and Proxy Applications
We evaluate CUDA, HIP, SYCL, Kokkos, RAJA, OpenMP, and OpenACC using the following proxy apps:
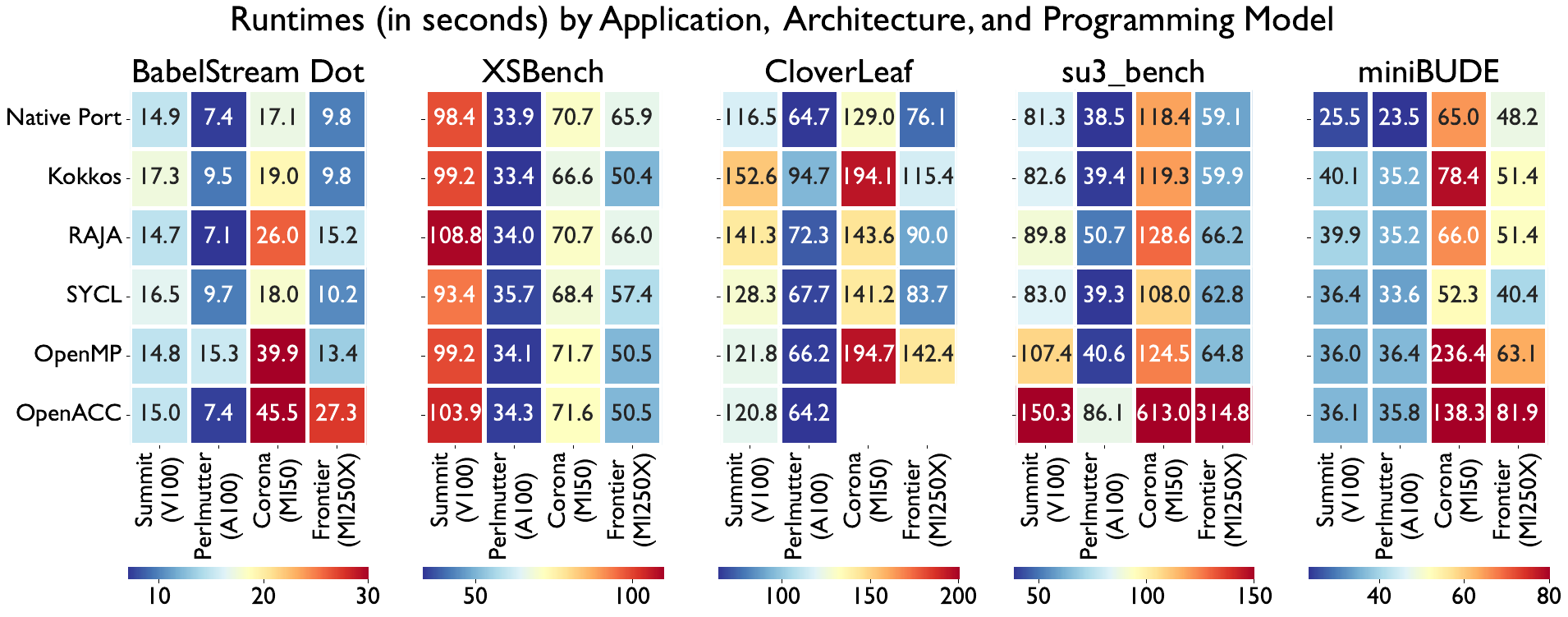
- BabelStream: a memory bandwidth benchmark with five kernels: copy, add, mul, triad, and dot. We focus on dot, which is a reduction operation, as it shows the greatest variation between programming models.
- CloverLeaf: a 2D structured compressible Euler equations solver in the Mantevo Applications Suite.
- XSBench: a proxy app for OpenMC (Monte Carlo) neutron transport code which represents the macroscopic cross-section lookup kernel.
- su3_bench: a proxy app for MILC Lattice QCD, implementing a complex number matrix-matrix multiply routine.
- miniBUDE: a molecular docking simulation kernel, which repeatedly computes the energy field for a single configuration of a protein.
Evaluation Platforms and Compilers
We present results on the following platforms:
- Summit (OLCF): IBM POWER9 CPUs with NVIDIA V100 (16 GB) GPUs.
- Perlmutter (NERSC): AMD EPYC 7763 CPUs with NVIDIA A100 (40 GB) GPUs.
- Corona (LLNL): AMD Rome CPUs with AMD MI50 (32 GB) GPUs.
- Frontier (OLCF): AMD Opt. 3rd Gen. EPYC CPUs with AMD MI250X (64 GB) GPUs.
The following compilers we used for each combination of system and programming model. Note that we use AdaptiveCpp 23.10.0 for SYCL CloverLeaf and ROCmCC for OpenMP su3_bench on AMD due to improved performance.
| Prog. Model | Summit | Perlmutter | Corona | Frontier |
|---|---|---|---|---|
| CUDA | GCC 12.2.0 | GCC 12.2.0 | N/A | N/A |
| HIP | N/A | N/A | ROCmCC 5.7.0 | ROCmCC 5.7.0 |
| Kokkos | GCC 12.2.0 | GCC 12.2.0 | ROCmCC 5.7.0 | ROCmCC 5.7.0 |
| RAJA | GCC 12.2.0 | GCC 12.2.0 | ROCmCC 5.7.0 | ROCmCC 5.7.0 |
| OpenMP* | NVHPC 24.1 | NVHPC 24.1 | LLVM 17.0.6 | LLVM 17.0.6 |
| OpenACC | NVHPC 24.1 | NVHPC 24.1 | Clacc 2023-08-15 | Clacc 2023-08-15 |
| SYCL* | DPC++ 2024.01.20 | DPC++ 2024.01.20 | DPC++ 2024.01.20 | DPC++ 2024.01.20 |
Reproducibility and Automation Strategy
In our experiments, we ensure that compilers, dependency versions, and flags are used consistently across applications and systems. We accomplish this with Spack, a popular HPC package manager. By creating a single Spack environment for each system which specifies exact compiler, app, and dependency versions, we ensure the software used for each test case is kept as consistent as possible.
These Spack environments can be easily adapted to any new system, allowing for easy reproduction of our experiments, and significantly reducing the extremely time-consuming effort of building every combination of application and programming model. We further employ Spack’s Python scripting tools to develop robust automation for our experiments — we can create jobs with a single-line invocation leveraging Spack’s spec syntax to adjust which application, models, or compilers are used, and save profile data to disk to be directly read by our plotting scripts. These scripts and environments will be published to allow the community to use our portability study methodology.
Results
Below we present the latest performance results of five mini-applications in seven programming models across four hardware platforms. All data points represent an average over three trials, with one warm-up execution performed before measurement. Note that results do not include data movement to and from the device.
Optimizations for Performance Portability
In our full paper, we present performance portability optimizations for a few chosen outliers from our broader results. These optimizations include rearranging directives, changing the level of parallelism exposed, and improving use of hardware features. We direct readers to our arXiv submission [1] for more information and an updated set of full results with our optimizations.
Related Publications
[1] et al, "",
[2] Joshua H. Davis et al, "Evaluating Performance Portability of GPU Programming Models", Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’23, November 2023